Table of Contents
Introduction
This article will provide you with common mapper problems and solutions, i.e., some BizTalk Mapper Patterns specifying best practices and some of the best ways to address some of your needs within the context of message transformation and also to enhance your skills when using the BizTalk Server Mapper.
Grouping
One of the more challenging things to do in BizTalk Mapper is to make grouping values operations, i.e., getting a distinct list of values from a set of nodes/elements and do grouping operations over that list of values. For accomplish this we need to use custom XSLT and there is no simple syntax to write this type of XPath query in XSL 1.0 (however this is very easy to do in XSL 2.0).
When grouping nodes, we also think in sort things to get them into a certain order, then we group all items that have the same value for the sort key (or keys). We'll use xsl:sort for this grouping, then use variables or functions like key() or generate-id() to finish the job.Using preceding-sibling expression
The preceding-sibling axis contains all the preceding siblings of the context node; if the context node is an attribute node or namespace node, the preceding-sibling axis is empty.
Basically, the expression checks the value of every preceding-sibling and returns True when none of the preceding-sibling elements has the same value that we are validating or False otherwise. This expression is used in conjunction with xsl:for-each element.The xsl:for-each element will loop through the first occurrence of each unique grouping value and the preceding-sibling expression will validate the previous existence, emulating this way the existence of a list of unique values.
The following is a list of resources that explain how to accomplish this:
This algorithm is not efficient for large messages but work well for ‘normal’ messages. For large messages Muenchian method is generally more efficient than using preceding-sibling.
The trouble with this method is that it involves two XPaths that take a lot of processing for big XML sources. Searching through all the preceding siblings with the 'preceding-siblings' axis takes a long time if you're near the end of the records. Similarly, getting all the elements with a certain values involves looking at every single element each time. This makes it very inefficient.
Using Muenchian method
The Muenchian Method is a method developed by Steve Muench for performing the previous functions in a more efficient way using keys. Keys work by assigning a key value to a node and giving you easy access to that node through the key value. If there are lots of nodes that have the same key value, then all those nodes are retrieved when you use that key value. Effectively this means that if you want to group a set of nodes according to a particular property of the node, then you can use keys to group them together.
When leading with large files, speed processing is vital. Classical Muenchian grouping use generate-id(). Muenchian grouping using generate-id() is slowest that using count() function , and shows worst scalability. Probably the reason is poor generate-id() function implementation. In other words, count() function performs is much better.
So to improve Muenchian a little more we have to use count() function instead of generate-id():
<xsl:for-each select="Order[count(. | key('groups',OrderId)[1]) = 1]">The following is a list of resources that explain how to accomplish this:
- Muenchian Grouping and Sorting in BizTalk Maps
- BizTalk Training – Mapping – Muenchian Grouping and Sorting in BizTalk Maps without losing Map functionalities
- BizTalk Training – Mapping – How to implement multi-level Muenchian grouping in BizTalk Maps
- How to speed up Muenchian grouping in .NET
Grouping elements from different messages
The previous two options are related with group operations associated with the same message, but if we want to combine values from different messages into the same output message. For example: we have a message with user information and another message that have addresses, and each user can have multiple addresses, we want to combine data from two different messages and we want to group all user and addresses information into one single message.
The following is a list of resources that explain how to accomplish this:Calling an external assembly from Custom XSLT
In complex maps is usual to have scripting functoid with custom inline XSLT, and sometimes is useful to call custom .Net components directly from XSLT. There are two cases in which you will need to build your own custom extension XML file and set the Custom Extension XML file to refer to it, as follows:
- If you use the Custom XSLT Path property to specify your own XSLT for the entire map file and you call an external .NET assembly from your XSLT, you are responsible for creating a properly formatted custom extension XML file that provides the appropriate namespace-to-assembly binding.
- If you use the Inline XSLT or the Inline XSLT Call Template script types in a Scripting functoid and you call a method in an external .NET assembly from that XSLT, you are responsible for creating a properly formatted custom extension XML file that provides the appropriate namespace-to-assembly binding. This is required because BizTalk Mapper does not parse into the XSLT you provide looking for calls to external assemblies. Any binding information you provide by using the Custom Extension XML property will be appended to any binding information that has already been generated when the map was compiled (such as bindings required by other Scripting functoids in the map that use the external assembly option). When you validate the map, the resulting contents of the custom extension XML file contain the union of the binding information you provided and any binding information generated by BizTalk Mapper.
- BizTalk Mapper Patterns: Calling an external assembly from Custom XSLT in BizTalk Server 2010
- Calling an external assembly from Custom XSLT – Custom Extension XML (Grid Property)
Working with Name/Value Pair Structures
It is very normal for us to work with Name/Value Pair structures inside the schema, this type of problem happens with some regularity, either mapping one Hierarchical Schema to a Name Value Pair or the reverse process.
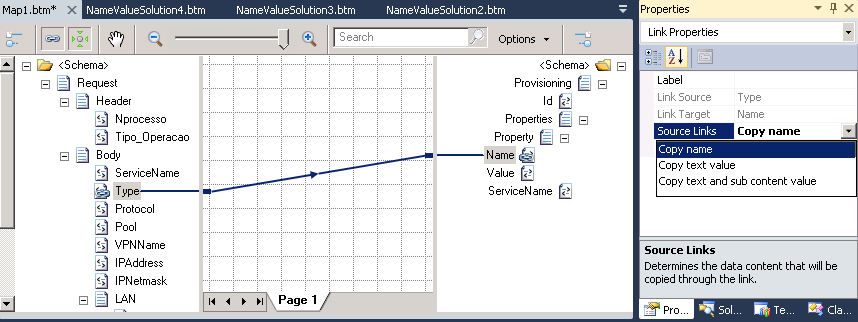
The major problem with this type of mapping is that it can be done in many different ways: some ways quite simple to implement, but with serious performance problems or difficult to maintain; other difficult to implement; dynamic mapping and so on. Therefore it is good to know what alternatives possible as well as their advantages and disadvantages.The basic thing we need to know is how I can read the name of the element from the source schema. By default when we drag a link from the source to the destination schema, the value of the element is mapped in the destination schema, but we can change this behavior in the link properties by choosing “Copy name” in the “Source Links” property:
- BizTalk Mapper Patterns: How to Map Hierarchical Schema to a Name Value Pair
- BizTalk Mapper Patterns: How to Map Name Value Pair to a Hierarchical Schema
See Also
Read suggested related topics:
- BizTalk Server: Basics principles of Maps
- BizTalk Server: How Maps Work
- BizTalk Server 2010: Mapper
- BizTalk Virtual Mapper VS Custom-XSLT
Back to Top